
Crowdsourcing efforts in astronomy have led to recent discoveries, such as material orbiting star KIC 8462852. The anomalous pattern was detected by citizen scientists using the Planet Hunters tool, initiated by researchers at Yale University.
Memory institutions across Europe hold millions of documents and works of art that they would like to make digitally available. But the cost of clearing copyright in each one presents costs that many institutions can’t overcome. CREATe researchers are involved in a new project to explore how crowdsourcing can help museums and archives search for rightsholders and clear permission to use these works. The project, titled ‘Enhancing access to 20th Century cultural heritage through Distributed Orphan Works clearance’ (EnDOW) is led by Professor Maurizio Borghi at Bournemouth University. The research team consists of investigators from Bournemouth University (CIPPM), Bocconi University Milan (ASK), University of Glasgow (CREATe) and the University of Amsterdam (IViR).
Taking lessons from two successful crowdsourcing initiatives in Astronomy: Seti@home and the Kepler Planet Hunters project, in this post I explore how balancing the costs and benefits of crowdsourcing is a challenge requiring care and planning. Getting the most out of crowdsourcing requires paying attention to a feature called the ‘computability to content ratio’, as well as enabling paths to ‘private-collective innovation’ for users with different levels of commitment. Lessons for design of crowdsourcing initiatives are discussed.
Crowdsourcing emerged alongside the adoption of networked digital technologies. The term came to prominence in the early 2000s in Wired Magazine to describe new management practices made possible with digital communication tools. These facilitating technologies include collaborative knowledge tools such as Google maps or software development platforms like GitHub, which allow groups of users to contribute information to a collective project.1 Crowdsourcing is distinct from other collective uses of digital technology such as commons-based peer production2 or produsage3. Unlike co-productive practices where participants choose their own roles, crowdsourcing is typically initiated for a specific purpose and seeks inputs which are more clearly defined than for collectively owned projects. Crowdsourcing is typically initiated in pursuit of either economies of scale or economies of scope. Each of these aims has consequences for the way that crowdsourcing platforms are designed and both have potential applications to the challenge of copyright diligent search.
Economies of scale
Crowdsourcing efforts which seek to benefit from economies of scale need to attract a large enough group of contributors to spread a task in such a way that each individual’s input is lower than their threshold to contribute (typically very low for internet communities). The challenge for crowdsourcing is to attract and solicit contributions from a large enough group of contributors to make the project worthwhile. Contributors do not always require external incentives to participate in crowdfunding efforts. As von Hippel and von Krogh note, for many collective projects, ‘when the expected costs of free revealing are low, even a low level of reward can be sufficient to induce the behavior’.4 However, the costs to contribute must match the expected benefits. This means that crowdsourcing systems must be streamlined to reduce costs, have very low barriers to use, be easily understandable and accessible. If individual users are asked to contribute too much, their input will be lost.
One example of crowdsourcing to benefit from economies of scale is the astronomy project SETI@home. This initiative is a public volunteer computing project with over 1.5 million contributors, hosted by the Space Sciences Laboratory at the University of California Berkeley. This project uses distributed computing to address challenges in the Search for Extraterrestrial Intelligence (SETI). SETI currently uses radio astronomy techniques to search for signals of artificial origin from beyond the solar system.
Data analysed by the SETI@home project is obtained by piggybacking on other research conducted at the Arecibo radio observatory in Puerto Rico. The broad spectrum radio data are passed along to the program and then parsed into smaller ‘chunks’ which are analysed for specific patterns by the computers of contributing volunteers. Crowd members who participate in SETI@home do not have any direct input into processing the data – this is done automatically. Volunteers simply agree to install the software on a device and allow it to run in the background. In order for data to be suitable for a crowdsourcing effort, it must have a high computability to content ratio.5 This means that the work done to analyse each ‘chunk’ of data must be greater than the work used to parse and transmit the chunks. As the network scales in size, the bandwidth needed to transmit work packets to contributors remains low, while data returned from distributed computation remains valuable.
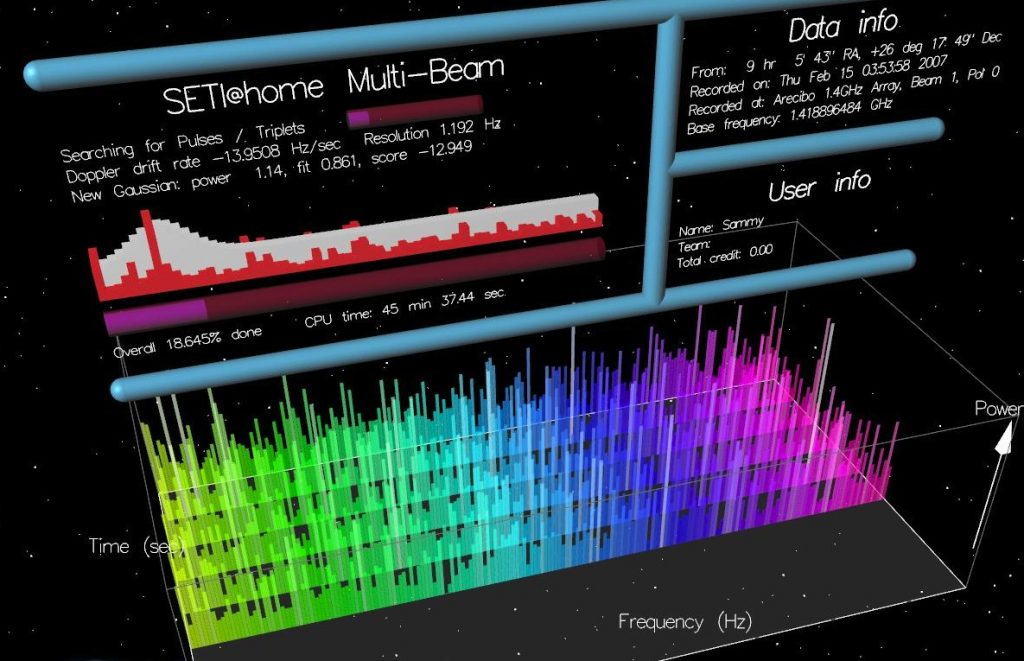
A screenshot showing the SETI@home client software running on a distributed node.
SETI@Home has been a tremendous success from a public relations perspective. It has brought in new users unfamiliar with the aims and goals of SETI and raised awareness of radio astronomy. So far, the initiative has not produced significant results in the search for ETI, however the knowledge gained from the initiative has been used to improve other distributed computing projects such as folding@home.
SETI@home has encountered organisational challenges relating to its interaction with the ‘crowd’. In one case, a group of computer coders, unhappy with the way the client software worked, created unauthorised versions of the software which improved processing performance. However the unauthorised fork in development could not reliably interface with the standard SETI@home software, raising problems for validity.5 In that case, crowdsourcing initiators suffered from an embarrassment of riches: contributors were so keen to provide their expertise that it produced extra unanticipated costs for the developers. The initiating institution was unwilling or unequipped to incorporate all user-led improvements (the project really only sought the standardised data input from users). If projects fail to provide an opportunity for users to propose meaningful improvements, this may represent a loss for those that pursue only efficiencies of scale in their approach to user input.
Economies of scope
Not all crowdsourcing initiatives seek to benefit from the scale of contributions. Another aim for organisations pursuing crowdsourcing is to benefit from efficiencies of scope. This means gathering the largest amount of possible perspectives on a problem to explore solutions. Project initiators in this case may lack resources to pursue all innovative possibilities and thus seek input from external users and experts. Research on user-led innovation in sports equipment manufacturing has found that under certain conditions, users do a better job of innovating new product features than commercial manufacturers.6
One motivation for users to engage in crowdsourcing of this type is that contributors can benefit from ‘selective incentives’ which arise from the process of contribution and are only available to those who actively contribute.7 These benefits can include knowledge and skill building as well as reputational gains. In commercial contexts, users may benefit if their ideas are adopted by the project initiator and it leads to feature changes that benefit them.8 Research has found that this is an important incentive for participation in open source software development.9 So, as with large-scale crowdsourcing efforts, it is not always necessary to offer a monetary reward for participation – costs relate to the design and initiation of the project.
An example of crowdsourcing for efficiencies of scope in astronomy is the Planet Hunters project, initiated by Yale University in 2011 alongside the NASA Kepler mission. The Kepler telescope searches for evidence of planets orbiting stars outside our solar system as they pass in front of (transit) a star from the perspective of Earth, dimming the light from the star. Data from the mission consist of observations of the light curves produced by watching some 145,000 main sequence stars over the 3.5 year period of initial observation.
The Planet Hunters crowdsourcing initiative is hosted on the Zooniverse.org platform, where ‘citizen scientists’ can flag up patterns observed in the transit data. Users must be lightly trained in order to input useful data, which depends on human judgment about trends or patterns that may not be detectable my a software algorithm. This project aims to benefit from efficiencies of scope provided by users who exercise judgment in analysing patterns. An organiser of Zooniverse calls it ‘distributed thinking, not distributed computing’.10
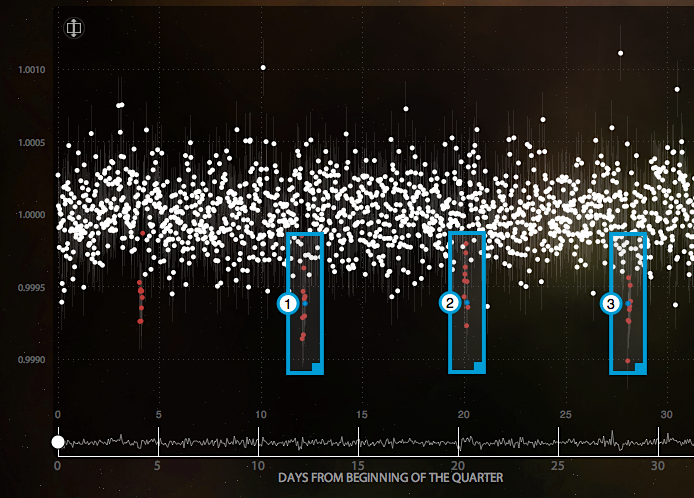
An example of user contribution on the Planet Hunters tool. Annotations show where a user has identified a possible planetary transit.
The Planet Hunters project has yielded research success. A significant number of new planetary candidates (PCs) have been identified by human contributors to the initiative. One unusual Kepler star, KIC 8462852, was flagged up as unusual by crowd contributors, which led to deeper investigation of its unusual light curve. This discovery led to a number of scientific publications with citizen scientists as co-authors.11 12
The challenges of crowdsourcing for efficiencies of scope in scientific knowledge production are similar to those facing commercial innovators. Some of the public critiques of the Zooniverse.org platform relate to the hierarchical structure of the crowdsourcing endeavour and the relative low status of user-contributors.13 One blogger has wondered, ‘Isn’t citizen science simply scientists making the public do the boring parts of science for them?’.14 These questions have implications for the structure and organisation of crowdsourcing projects: What is the status of ‘citizen scientists’ with respect to ‘real’ scientists? How do crowdsourcing initiatives of this type distribute access to data in a way that benefits from ‘efficiencies of scope’ while still protecting the professional role of scientists (or in our case, archivists) that depend on proprietary data for career progression and funding?
One way that the Planet Hunters initiative succeeded is by offering a range of levels of contribution. Unlike the SETI@home project, the Planet Hunters initiative is supported by additional communication channels that enable feedback from user-contributors. Indeed, most of the significant scientific insights produced by the project thus far have come from communities of practice which coalesced in forums parallel to the Planet Hunters website. Selective incentives appear to dominate in this space – contributors who put in more effort and expertise gain increased status, opportunity and experience through these channels.
Lessons for Digital Cultural Heritage
Crowdsourcing copyright orphan works clearance shares similarities with the task facing both the SETI@home and Planet Hunters projects. For one thing, the number of works held by cultural institutions is almost as vast as the stars in the sky. Even a relatively small project currently underway by the University of Glasgow to digitise portions of the Edwin Morgan scrapbooks contains upwards of 48,000 unique copyright works across 12 volumes. Large institutional collections regularly reach into the tens of millions of individual works, posing a considerable challenge for rights clearance.15 Spreading the task of diligently searching for rightsholders across a crowd of contributors would reduce costs for institutions who do not possess adequate resources in terms of staff or funding.
The process of clearing copyright orphan works could also benefit from efficiencies of scope. Handling an unknown work requires knowledge and expertise about its age, provenance and context. This is usually the domain of the professional archivist. However, like the flattening of expertise involved in crowd astronomy projects like Planet Hunters, the trained archivist may be able to benefit from wisdom and expertise contained in a heterogeneous crowd.
Any crowdsourcing initiative in this space must be conscious of costs. These include the cost of individual contributions, which must be low enough to ‘induce the behaviour’ of sharing by members of the crowd. However, the initiative will also bear costs for institutions. The cost of setting up a distributed system and administering it must be lower than the cost of hiring a trained archivist to do the job of rights clearance – this lends itself to large collections where the marginal addition of new public contributors adds value to the endeavour. Finally, the design of a platform for crowdsourcing copyright clearance should take account of the costs related to the flow and processing of information on both ends. Crowd contributors need some information about the copyright work to be cleared (in fact, the work must be pre-digitised). These costs must be lower than the cost of rights clearance itself (the computation done by nodes in the crowd). The difference between these two costs represents the efficiency of scale gained by crowdsourcing the diligent search. Marginal cost should decrease as a function of the size of collection to be digitised. Imagine if the SETI@home project required server-side processing that exceeded the computation accomplished by nodes. This would defeat the purpose of distributing the work.
Crowdsourcing likely offers a solution to some of the problems facing archival institutions with respect to copyright clearance. However, it may not be suitable to all institutions or all collections. Understanding the costs and benefits of crowdsourcing will help the research team identify where the EnDOW platform can offer the most benefit.
Key recommendations:
• Reduce the cost of contributing to below the private benefits expected from individual contributors
• Enable selective benefits by permitting contributors to take a stake in the collective outcome of the project and enable that contribution
• Lower the cost of transmitting information to below the benefit of distributing the task.
Notes:
1. Burgelman, J. C., Osimo, D., & Bogdanowicz, M. (2010). Science 2.0 (change will happen….). First Monday, 15(7).
2. Benkler, Y. (2006). The Wealth of Networks: How Social Production Transforms Markets and Freedom. New Haven, CT: Yale Univ. Press.
3. Bruns, A. (2013). From Prosumption to Produsage. In Ruth Towse and Christian Handke (eds) Handbook on the Digital Creative Economy, pp. 67-78. Cheltenham: Edward Elgar.
4. Von Hippel, E. & Von Krogh, G. (2003). Open source software and the “private-collective” innovation model: Issues for organization science. Organization science, 14(2), p. 209-223.
5. Anderson, David P., Jeff Cobb, Eric Korpela, Matt Lebofsky, and Dan Werthimer. “SETI@ home: an experiment in public-resource computing.” Communications of the ACM 45, no. 11 (2002): 56-61.
6. Hienerth, C., von Hippel, E., & Jensen, M. B. (2014). User community vs. producer innovation development efficiency: A first empirical study. Research Policy, 43(1), 190-201.
7. von Hippel, E. (2005). Democratizing Innovation. Cambridge, MA: MIT Press.
8. Harhoff, D. Henkel, J. and Von Hippel, E. (2003). Profiting from voluntary information spillovers: how users benefit by freely revealing their innovations. Research policy, 32(10), p. 1753-1769.
9. Henkel, J., (2006). Selective revealing in open innovation processes: The case of embedded Linux. Research policy, 35(7), 953-969.
10. Lintott, C. (2010). ‘Citizen’ Science and ‘Real’ Science. Zooniverse blog 29 December 2010. Accessed online: http://blog.zooniverse.org/2010/12/29/citizen-science-and-real-science/
11. Boyajian, T. S., LaCourse, D. M., Rappaport, S. A., Fabrycky, D., Fischer, D. A., Gandolfi, D., … & Vida, K. (2015). Planet Hunters X. KIC 8462852-Where’s the Flux?. arXiv preprint arXiv:1509.03622.
12. Wright, J. T., Cartier, K., Zhao, M., Jontof-Hutter, D., & Ford, E. B. (2015). The Search for Extraterrestrial Civilizations with Large Energy Supplies. IV. The Signatures and Information Content of Transiting Megastructures. arXiv preprint arXiv:1510.04606.
13. Wright, Alex (2010). Managing Scientific Inquiry in a Laboratory the Size of the Web. New York Times, 27 December 2010. Accessed online: http://www.nytimes.com/2010/12/28/science/28citizen.html
14. Wills, E. (2014). Zooniverse. Faculty of Natural Sciences Student Blogs, 26 January 2014. Accessed online: http://wwwf.imperial.ac.uk/blog/studentblogs/emma13/2014/01/26/zooniverse/
15. Stobo, Victoria, R. Deazley, and I. Anderson. Copyright and Risk: Scoping the Wellcome Digital Library Project. No. 10. CREATe Working Paper, 2013.